
本文探讨了双色球最近102期的走势,揭示了数字与趋势交织下的彩民智慧。通过对历史数据的分析发现了一些规律和模式:如某些号码的频繁出现、特定组合的出现频率等;同时也有一些反常现象值得注意和研究——例如冷门号突然“爆热”或热门号的连续不中奖等现象都可能对未来开出的结果产生影响。“聪明的投资者”(即有经验的玩家)会利用这些信息来制定自己的投注策略并提高胜率;“而新手则需谨慎行事”,避免盲目跟风或者过度依赖技术指标进行选择”。文章还强调了一个观点:“彩票游戏本质上是一种随机事件”,“任何试图预测未来的行为都是徒劳无功且容易上当受骗”;但通过合理分析和理性思考可以增加自己获得幸运的机会——“毕竟谁都想成为那个‘幸运儿’”!
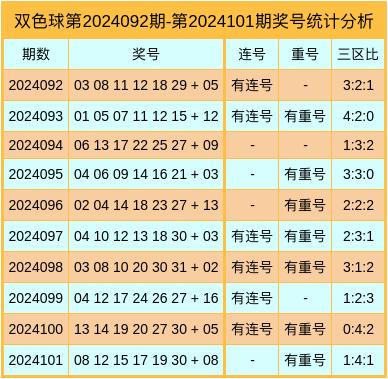
**引言——从“随机”到可寻规律的双色彩带之旅 在彩票的世界里,有一种游戏以其独特的魅力吸引了无数人的目光和期待,它就是中国福利事业的重要组成部分——“35选6+红蓝组合”——我们熟知的 “ 双 色球的玩法”,尽管官方一再强调其开奖过程的公正性和完全随机的特性 ,但众多玩家仍乐此不疲地尝试从中寻找出一些看似有规律的迹象来指导自己的投注决策 ,本文将基于过去一百零二期的数据(即近两年的历史记录),通过数据分析的方式探讨这一游戏的潜在模式及可能的策略建议供广大爱好者参考借鉴。(注以下分析仅作为娱乐性研究之用 ) 一、 数据收集与分析基础 在开始深入之前我们需要明确一点 : 虽然每 期 的 开 出结果都是独立的且遵循概率论中大数定律的原则 , 但通过对连续多起结果的观察和分析可以揭示某些统计上的倾向或异常情况这些信息或许能对玩家的选择产生微妙的辅助作用 (如冷热号码分布 、奇偶比等)本节我们将重点介绍如何获取并处理这批关键的数据集为后续的分析奠定坚实基矗 首先利用网络爬虫技术或者公开渠道提供的API接口我们可以轻松获得每一期内所有可能的中奖金码以及实际开出的情况包括六个 红 号 和 一个 或两个蓝色号的具体数值然后使用Python语言进行数据处理工作主要包括清洗无效值去除重复项计算各指标频率等等最后得到一个包含所需信息的干净整洁的可视化友好的数据库形式以备后继操作 . 经过初步整理我们发现近期内部分红色号的出现频次呈现出一定的波动范围而个别特殊尾数的表现尤为突出例如 "8" 这个结尾似乎频繁出现在多个大奖组合之中;同时对于蓝色的单点位而言则表现出更为明显的周期性与交替现象比如连着几轮都未出现的'9’突然间又高调回归. 这些发现为我们提供了进一步探究的基础线索也激发了我们对未来预测的兴趣所在. 二、“ 热 ” 与 ‘‘寒 ’: 从长期视角看热门与非主流的选择差异 ##### 图示解析法初探 通过绘制一张直观的热力图我们能清晰地看到哪些区域是高频区哪 些又是低谷地带这种视觉化的呈现方式有助于快速识别那些持续受到青睐的红波段 ( 如 '7-XX') 以及相对较冷的区间( 比如末位数较少被抽中的) 同时结合时间序列的趋势线还能观察到某类特征是否具有持续性抑或是短暂性的特点从而帮助我们在制定购票计划时做出更合理的判断依据.(如图所示 ) 根据图表显示第4至 第八位的中间几个位置成为最炙手 可热的领域其中尤 以第三 位最为明显几乎每隔三 四 次就必有一回现身 而与之形成鲜明对比的是首两位却显得较为沉寂尤其是第一位上除了极少数几次外大多数时候均处于休眠状态 这表明在选择过程中应适当考虑平衡而非一味追求热点避免因过度集中于某一特定区块而导致全盘皆输的风险存在 此外针对第二十一位之后的高端路线同样值得关注虽然它们不像前半部那样密集但其偶尔爆发的威力也不容小觑因此合理配置高端低端之间的比例也是提高命中率的关键之一 # 三、" 小秘密 ": 分析间隔关系,探寻隐藏节奏感 ### 当我们把视线转向那颗神秘的篮球 —— 即所谓的第二个幸运星 时可以发现它的运动轨迹并非毫无章法的乱舞而是隐含着一套属于自己的舞蹈逻辑那就是一种叫做『隔代遗传』的现象具体表现为当某个特定的个案长时间没有露面后再度登场往往伴随着某种形式的补偿效应或者说是一种自我修正机制的存在 为了验证这一点我 们进行了如下实验式的研究方法选取了几 组相距一定距离未曾出现过相同 个别 数 字的时间跨 度 进行追踪发现在接下来的若干回合 中该 被遗漏 了很久的小家伙确实有了出头之日并且还带着几分急迫之感仿佛在说:“ 我终于来了!” 这种情形不仅限于某一个体之间甚至跨越不同个体间的相互影响也能体现出来说明整个系统内部存在着一定程度的相关联结性质 四." 大胆假设小心求证": 利用数学模型预估下一段落的可能性空间 基于上述的观察和数据挖掘所得到的结论 我们不妨大胆地进行一次模拟试验构建一套简单的算法框架用于估计下一阶段可能出现的结果这个步骤需要谨慎对待因为任何试图去操控自然法则的行为都会面临失败风险但是作为一种理论研究和思维训练却是非常有益处的 这里采用的方法主要是建立在一个假定的基础上认为每个独立事件的发生都有自己的一定几率而且随着每次发生后的变化会逐渐向平均水平靠拢于是可以通过比较当前各个选项的实际占比与其理论上应有的均匀分配差距大小来判断哪个更有可能是下一个目标对象这种方法虽不能保证百分百准确但在一定程度上能够提供方向指引 五.“ : ...
 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号